核心概念解析
神经网络基础
模仿人脑的信息处理方式
就像人脑的神经元
人脑有数十亿个神经元相互连接,形成复杂的网络。神经网络就是用数学方式模拟这个过程:
- 输入层:接收信息(比如一个句子)
- 隐藏层:处理和分析信息(可能有很多层)
- 输出层:产生结果(比如回答或翻译)
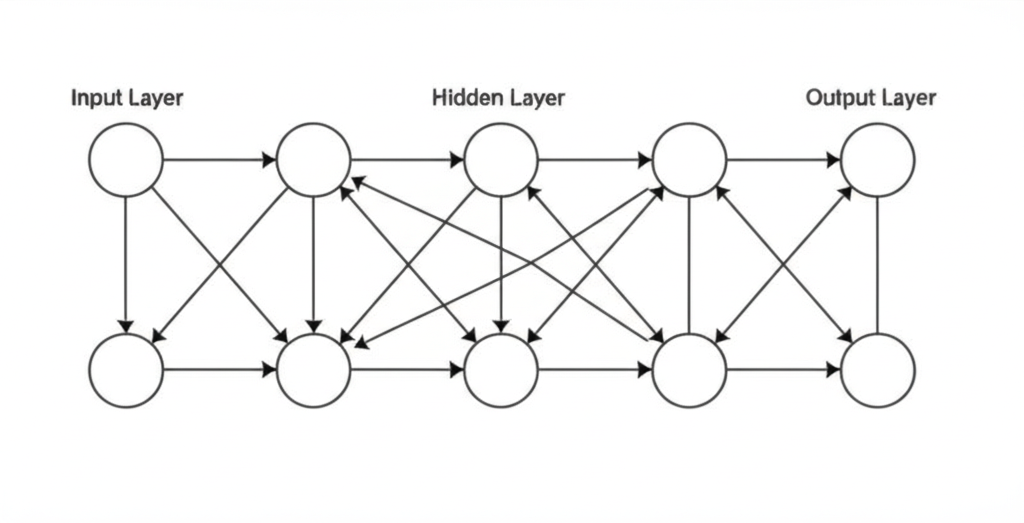
简单的神经网络示例
这是一个用 Python 实现的简单神经网络示例:
python
import numpy as np
class SimpleNeuralNetwork:
def __init__(self):
# 初始化权重
self.weights = np.random.random((3, 1))
def sigmoid(self, x):
# 激活函数
return 1 / (1 + np.exp(-x))
def forward(self, inputs):
# 前向传播
return self.sigmoid(np.dot(inputs, self.weights))
# 创建神经网络
nn = SimpleNeuralNetwork()
# 输入数据 [输入1, 输入2, 输入3]
inputs = np.array([[0, 0, 1], [1, 1, 1], [1, 0, 1]])
# 预测输出
output = nn.forward(inputs)
print("预测结果:", output)Transformer 架构
现代LLM的核心技术
注意力机制 (Attention)
想象你在读一本书时,会特别关注重要的词语。Transformer 也是这样工作的:
"小明喜欢苹果因为它很甜。"
模型知道"它"指的是"苹果",而不是"小明"
- 自注意力:理解句子中词语之间的关系
- 并行处理:同时处理整个句子,而不是逐词处理
- 位置编码:记住词语在句子中的位置
